Merhabalar, bir önceki yazımızda Docker Swarm Mode’a giriş yapmış ve temel terimleri öğrenmiştik. Bu yazımızda ise local bilgisayarımızda bir Swarm Cluster oluşturucağız ve uygulamamızı Docker Swarm üzerinde çalışmasını sağlayacağız.
Hazırlıklar
Öncelikle local bilgisayarda bunu yapacağımız için sanal makinalar oluşturmamız gerekmekte. Bunu vm / vagrant / docker-machine vs ile yapabilirsiniz. Ben docker-machine ile oluşturmayı tercih edeceğim.
Docker machine
Üzerinde Docker Engine olan sanal bilgisayarlar olusturmanıza olanak sağlayan bir araçtır. Mevcut bazı driverlar ile local de yada cloud da makinalar oluşturabilirsiniz. Başlayalım;
Bildiğiniz gibi bir önceki yazımızda Master ve Worker node’lardan bahsetmiştik. Swarm cluster içerisinde master olarak rol vereceğimiz sunucu için predator-master adında bir makina oluşturalım;
docker-machine create --virtualbox-memory "1024" --virtualbox-disk-size "4096" --driver "virtualbox" predator-master
Hemen ardından worker node oluşturalım;
docker-machine create --virtualbox-memory "1024" --virtualbox-disk-size "4096" --driver "virtualbox" predator-worker
Oluşturduğumuz makinaları listeleyelim;
alican.akkus@iyzi-sfd-11 ~ docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
predator-master - virtualbox Running tcp://192.168.99.100:2376 v18.01.0-ce
predator-worker - virtualbox Running tcp://192.168.99.101:2376 v18.01.0-ce
alican.akkus@iyzi-sfd-11 ~
Master node ip -> 192.168.99.100 Worker node ip -> 192.168.99.101
Hemen ardından da master makinasına bağlanalım;
docker-machine ssh predator-master
Bağlandıktan sonra docker swarm’ı init edeceğiz.
docker swarm init ile oluşturmak istediğimiz de hata alıyor olacağız.
docker@predator-master:~$ docker swarm init
Error response from daemon: could not choose an IP address to advertise since this system has multiple addresses on different interfaces (10.0.2.15 on eth0 and 192.168.99.100 on eth1) - specify one with --advertise-addr
docker@predator-master:~$
Docker burada bize bir network interface tercih etmemizi söylemekte. Şöyle çalıştıralım;
docker@predator-master:~$ docker swarm init --advertise-addr eth1
Swarm initialized: current node (35z3kghkfdsj5cqni7zkg4tel) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-13yjhezthsd5qocdu1s5viifot0cc0mka8budhew801wse4rrz-epuvowr9qkh3ev9yif23esgwl 192.168.99.100:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
docker@predator-master:~$
Docker Swarm cluster init edilmiş oldu. Docker swarm’a worker olarak katılmak isteyen nodelar da ise yukarda yer alan komutu çalıştırmamız yeterli olacaktır. Şu anda cluster içerisinde sadece tek bir node olan master node bulunmakta.
Bu şekilde de uygulamalarımızı swarm üzerinde koşturabiliriz bu arada. Şimdi ikinci bir terminal ile worker makinasına bağlanalım. Yukarda yer alan docker swarm join –token …. ifadesini kopyalayalım.
alican.akkus@iyzi-sfd-11 ~ docker-machine ssh predator-worker
docker@predator-worker:~$ docker swarm join --token SWMTKN-1-13yjhezthsd5qocdu1s5viifot0cc0mka8budhew801wse4rrz-epuvowr9qkh3ev9yif23esgwl 192.168.99.100:2377
This node joined a swarm as a worker.
docker@predator-worker:~$
Swarm cluster’a worker olarak katıldığımızı görebiliriz. Şimdi master node’a geçelim ve cluster durumunu gözetleyelim;
docker@predator-master:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
35z3kghkfdsj5cqni7zkg4tel * predator-master Ready Active Leader
lbh3n4hutxylw3a3xnz9ee48p predator-worker Ready Active
docker@predator-master:~$
Cluster içerisine dahil olan 2 node’u görebiliriz. İkisi de active, ready durumunda. Manager status kısmında master olan node için Leader ifadesini göreceğiz.
Şimdi örneklerle ilerlemeye çalışalım. Bir nginx ayağa kaldıralım.
docker@predator-master:~$ docker service create --mode global --name nginx nginx:1.13.8
eoa8us0qhqagt3ztquhtuoyd3
overall progress: 2 out of 2 tasks
lbh3n4hutxyl: running [==================================================>]
35z3kghkfdsj: running [==================================================>]
verify: Service converged
docker@predator-master:~$
Nginx 1.13.8 tag’i ile bir nginx olusturduk. Mode global parametresi ile service mode type’ı global seçtik bu sayede cluster’a dahil olan her node üzerinde bir instance çalışacaktır. Detayına bakalım;
docker@predator-master:~$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
eoa8us0qhqag nginx global 2/2 nginx:1.13.8
docker@predator-master:~$
Her node üzerinde çalışacağı için de bağlı olduğumuz master node üzerinden docker ps ile bakabiliriz;
docker@predator-master:~$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
24945d9245d5 nginx:1.13.8 "nginx -g 'daemon of…" 10 minutes ago Up 10 minutes 80/tcp nginx.35z3kghkfdsj5cqni7zkg4tel.usyqfd9db2jpkmwz9d7gf8bxu
docker@predator-master:~$
Şimdi service’i port expose edecek şekilde update edelim;
docker@predator-master:~$ docker service update --publish-add 8080:80 nginx
nginx
overall progress: 2 out of 2 tasks
35z3kghkfdsj: running [==================================================>]
lbh3n4hutxyl: running [==================================================>]
verify: Service converged
docker@predator-master:~$
Şimdi host makinamız üzerinden http://192.168.99.101:8080 veya http://192.168.99.100:8080 adreslerine gittiğimiz de bizi Nginx sayfası karşılayacaktır.
Şimdi service mode olarak replicated olarak işlem yapalım ve bazı constraint tanımı yapalım;
docker@predator-master:~$ docker service create --mode replicated --replicas=2 --constraint 'node.role==worker' --name nginx nginx:1.13.8
izxgeljk4ap7yf7m47uo9mxan
overall progress: 2 out of 2 tasks
1/2: running [==================================================>]
2/2: running [==================================================>]
verify: Service converged
docker@predator-master:~$
Replica yani çalıştırılacak instance adedi olarak 2 verdik ve kısıtlama olarak da bu servisin sadece worker rolündeki nodelarda çalışmasını istedik. Bu yüzden master node üzerinde docker ps komutunu çalıştırdığımızda bir çalışan bir container göremeyeceğiz. Aynı komutu worker node üzerinde çalıştıralım ve sonucu görelim;
docker@predator-worker:~$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4e4cd1f86d30 nginx:1.13.8 "nginx -g 'daemon of…" 2 minutes ago Up 2 minutes 80/tcp nginx.1.w8ztwtixydnyzzlk2qa6usdpm
fc50af25423f nginx:1.13.8 "nginx -g 'daemon of…" 2 minutes ago Up 2 minutes 80/tcp nginx.2.mojyce11ww384ksw6rg6lg1gh
docker@predator-worker:~$
Not : Dikkat ederseniz worker node üzerinden iki tane instance çalışmasına ve ikisi de kendini 80 portundan expose etmesine rağmen bir port çakışması olmadı. Yukarda belirttiğim adreslere host makina üzerinden eriştiğiniz de yine Nginx safyasını görüyor olacaksınız. Docker Swarm mode, master olan node üzerinde çalışan bir instance olmamasına rağmen gelen isteği worker’a iletti ve worker üzerinde iki instance olmasına rağmen port çakışması yaşanmadı ve aslında bir load balancing de yaparak gelen istekleri worker üzerinden çalışan iki instance arasında paylaştırdı. Thansk DOCKER!
Şimdi replica sayısını artıralım;
docker@predator-master:~$ docker service update --replicas=3 nginx
nginx
overall progress: 3 out of 3 tasks
1/3: running [==================================================>]
2/3: running [==================================================>]
3/3: running [==================================================>]
verify: Service converged
docker@predator-master:~$
Nginx servisini 3 instance’a çıkardık kolayca. Verdiğimiz kısıtdan dolayı 3 instance da worker üzerinde çalışmaya devam ediyor;
docker@predator-worker:~$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4e891189f73d nginx:1.13.8 "nginx -g 'daemon of…" 46 seconds ago Up 45 seconds 80/tcp nginx.3.oc9zkyr6k0d1vcdbwfirwemcs
eea30bb5395c nginx:1.13.8 "nginx -g 'daemon of…" 3 minutes ago Up 3 minutes 80/tcp nginx.1.l7iqaulwqdkbzk2hdxpcviefl
0ca5b65e364c nginx:1.13.8 "nginx -g 'daemon of…" 3 minutes ago Up 3 minutes 80/tcp nginx.2.hqqhcv3zpf2qsem2tjhhdc6kp
docker@predator-worker:~$
Not : Ayrıca olusturdugunuz master ve worker node’lara custom label vs tanımlayarak servis oluşturma anında bunları kullanabiliriz. Örn; node.type==development vs gibi.
Şimdi ise rolling update yapalım. Rolling update sayesinde zero down time ile sürüm değişikliklerini yapabilirsiniz. Örneğin eksi bir nginx versiyona geçelim;
docker@predator-master:~$ docker service update --image nginx:1.12.2 nginx
nginx
overall progress: 1 out of 2 tasks
1/2: running [==================================================>]
2/2: preparing [=================================> ]
Yukardaki çıktıya dikkat ederseniz Docker Swarm, çalışan 2 instance’dan birini önce update edip request almaya hazır hale gelmesini bekledikten sonra diğer instance’lara geçecektir. Bu esnada yapılan işlemleri şöyle sıralayabiliriz;
- Stop the first task.
- Schedule update for the stopped task.
- Start the container for the updated task.
- If the update to a task returns RUNNING, wait for the specified delay period then start the next task.
- If, at any time during the update, a task returns FAILED, pause the update.
Şöyle de detayına bakabiliriz;
docker@predator-master:~$ docker service inspect --pretty nginx
ID: alf40c34aplue5m2r5pzlf740
Name: nginx
Service Mode: Replicated
Replicas: 2
UpdateStatus:
State: completed
Started: 7 minutes ago
Completed: About a minute ago
Message: update completed
Placement:
UpdateConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Update order: stop-first
RollbackConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Rollback order: stop-first
ContainerSpec:
Image: nginx:1.12.2@sha256:547ea435d7d719b1a18b33e1a859b3ba0c81348d2f86d1d99ca1ba9c1422663e
Resources:
Endpoint Mode: vip
Ports:
PublishedPort = 8080
Protocol = tcp
TargetPort = 80
PublishMode = ingress
docker@predator-master:~$
Ayrıca swarm’a servisleri ikişer ikişer yada üçer üçer update et diyebilirsiniz. 10 instance olduğu durumda örneğin 2şer gruplar halinde update et diyebilirsiniz. Herhangi bir node üzerinde yapılan update işleminde hata alınır ise de tüm nodelar otomatik olarak rollback edilir.
Şimdi ise kompleks bir uygulamamızı swarm’a deploy edelim. Bir docker-compose ile docker swarm stack olusturacagız. Örnek için şuradaki git reposunu kullanacağız.
Öncesinde ayağa kaldıracağımız compose dosyasına bakalım. Docker compose konusuna yabancı iseniz blogda yer alan yazılara bakabilirsiniz.
version: "3.2"
services:
reverse_proxy:
image: dockersamples/atseasampleshopapp_reverse_proxy
ports:
- "80:80"
- "443:443"
secrets:
- source: revprox_cert
target: revprox_cert
- source: revprox_key
target: revprox_key
networks:
- front-tier
database:
image: dockersamples/atsea_db
environment:
POSTGRES_USER: gordonuser
POSTGRES_DB_PASSWORD_FILE: /run/secrets/postgres_password
POSTGRES_DB: atsea
networks:
- back-tier
secrets:
- postgres_password
deploy:
placement:
constraints:
- 'node.role == worker'
restart_policy:
condition: on-failure
delay: 5s
max_attempts: 3
window: 120s
appserver:
image: dockersamples/atsea_app
networks:
- front-tier
- back-tier
- payment
deploy:
replicas: 2
update_config:
parallelism: 2
failure_action: rollback
placement:
constraints:
- 'node.role == worker'
restart_policy:
condition: on-failure
delay: 5s
max_attempts: 3
window: 120s
secrets:
- postgres_password
visualizer:
image: dockersamples/visualizer:stable
ports:
- "8001:8080"
stop_grace_period: 1m30s
volumes:
- "/var/run/docker.sock:/var/run/docker.sock"
deploy:
update_config:
failure_action: rollback
placement:
constraints:
- 'node.role == manager'
resources:
limits:
cpus: '1.5'
memory: 500M
reservations:
cpus: '1'
memory: 20M
payment_gateway:
image: dockersamples/atseasampleshopapp_payment_gateway
secrets:
- source: staging_token
target: payment_token
networks:
- payment
deploy:
update_config:
failure_action: rollback
placement:
constraints:
- 'node.role == worker'
- 'node.labels.pcidss == yes'
networks:
front-tier:
back-tier:
payment:
driver: overlay
driver_opts:
encrypted: 'yes'
secrets:
postgres_password:
external: true
staging_token:
external: true
revprox_key:
external: true
revprox_cert:
external: true
docker-compose dosyamızda toplam 5 servis var görünüyor. Uygulamamızı front-tier, back-tier olarak ayırdık. Bazı kısıtlar vererek örneğin payment_gateway servisimizin worker node üzerinde ve pcidss(ödeme sistemlerini ilgilendiren bir tanım) label’in yes olduğu node üzerinde çalışmasını istedik.
Ayrıca bazı secretler kullandık. Bazı gizli/clear text olarak taşınmasını/görülmesini istemediğiniz dataları container’lara secretler aracılığıyla verebiliyorsunuz. Tabi compose dosyasını ayağa kaldırmadan bunların hazır olması gerekmekte. Bu nedenle git reposundaki açıklamalarda yer alan secret oluşturma kısmını atlamamalısınız.
Klasik olarak bir shop uygulaması yaptık. Uygulamamız appserver servisinden 2 tane instance olarak çalışacaktır. Bazı ek tanımlamalar yaptık. Mesela restart_policy olarak on-failure durumunda tekrar tekrar ayağa kalkmasını denemesini ve bunu en fazla max_attempts 3 tanımı ile kısıtladık. Bu tip tanımları business/logic/alt yapı ihtiyaçlarınıza göre ayarlayabilirsiniz.
Visualizer uygulaması ise shop uygulamasını ilgilendiren bir uygulama değildir. Sadece swarm ortamında çalışabilen özel bir uygulamadır ve swarm üzerinde çalışan servislerin bir UI aracılığı ile izlenebilmesini sağlar. Aşağıda olduğu gibi;
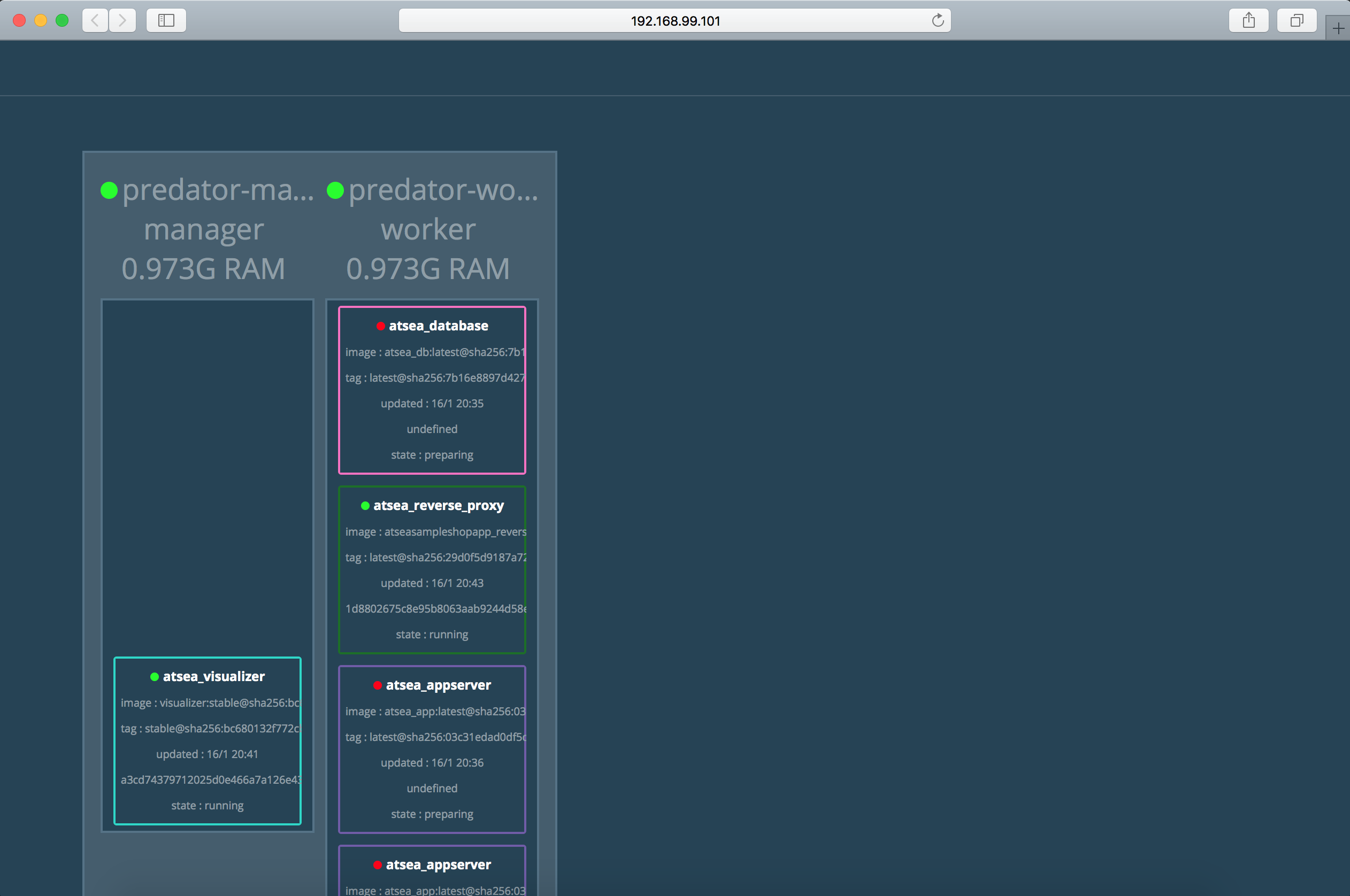
Compose dosyamızı swarma deploy edelim, bunun için yeni bir komut kullanacağız;
docker@predator-master:~/atsea/atsea-sample-shop-app$ docker stack deploy -c docker-stack.yml atsea-shop
Creating network atsea-shop_front-tier
Creating network atsea-shop_payment
Creating network atsea-shop_default
Creating network atsea-shop_back-tier
Creating service atsea-shop_payment_gateway
Creating service atsea-shop_reverse_proxy
Creating service atsea-shop_database
Creating service atsea-shop_appserver
Creating service atsea-shop_visualizer
docker@predator-master:~/atsea/atsea-sample-shop-app$
Swarm Stack’e bakalım;
docker@predator-master:~/atsea/atsea-sample-shop-app$ docker stack ls
NAME SERVICES
atsea-shop 5
docker@predator-master:~/atsea/atsea-sample-shop-app$
Birkaç dakika içerisinde eğer herşey yolunda gider ise tüm compose servisleri ayağa kalkacaktır.
Yazımızın sonuna gelmiş bulunmaktayız. Sizde buna benzer örnekleri local bilgisayarınızda deneyebilir, tecrübe edebilirsiniz.
comments powered by DisqusAlican Akkus.